Last Updated on January 10, 2016 at 7:10 am
In the second part 2, let us address the ‘kitna milega?’ with a little more analysis. The first part is here. Before we being to answer, what return one can expect, the objective of the study must be clear.
We will be using past data to figure out, for a given duration (say 15 years), what is the average return and how much individual returns can deviate from this average.
To what extent this can be done is a big question mark, as explained below. Assuming we can find
- the average return and
- the average deviation from the return
we will have to recognise that the average past return is not of much use. Future returns from equity as an asset class, combined the specific duration an investor will stay in equity implies that the past average has no bearing on the future average.
🔥Secure your future with our Robo-advisory tool trusted by over 3,000 investors and advisors. From effortless retirement planning to funding your children’s biggest dreams, turn your financial goals into reality. 🔥
Subscribe for money management solutions via email! (Link takes you to our email sign-up form) Join 32,000+ readers in our community.
👉 New Tool Alert! NaviPlan: A Privacy-Focused Multi-asset Tracker and Goal Planner 👈
However, 100+ years of US market history and 30+ years of our market history point to one indisputable fact:
regardless of when we measure and regardless of how long we measure it for, the volatility of the market is nearly constant!
To know more about this, read: Understanding the nature of stock market returns
Therefore, although the past average is not be of much use (future returns will depend on inflation, economy …), the past average deviation, or the spread about the average is important.
For example, we shall see below that for 15 year periods, individual returns can vary from the average by as much as 4%. We will understand how to interpret this 4% spread below.
I see no reason to believe that the next 15 years will have a lower spread. It can be higher, but 4% is what I would set as the minimum.
This is the objective of this post. To mentally prepare new equity investors to face the kind of fluctuations that the market has to offer. There is a misconception that things will get better with time. They will not! You need to review the folio at least annually.
The above spread is for a buy-and-hold portfolio. With a simple annual review, it may be possible to minimize this spread.
‘Kitna milega?’, nahi!
‘vichalan kitna hoga?’ (apologies for the poor Hindi. Vichalan is the closest I could find for deviation or spread.)
Instead of vichalan, Harrsh Ankola suggested at Asan Ideas for Wealth that, ‘kita hilega?’ would sound better. I agree.
Now over to the analysis.
The normal distribution
Mathematics is the language of nature and therefore of god (for those who choose to believe in one). If we try to avoid math and use our common tongue, we end up making mistakes or confusing ourselves and others.
One of the most extraordinary manifestations of nature is the so-called normal distribution. If we start measuring the blood pressures of a million people, the distribution of blood pressures would look like this.
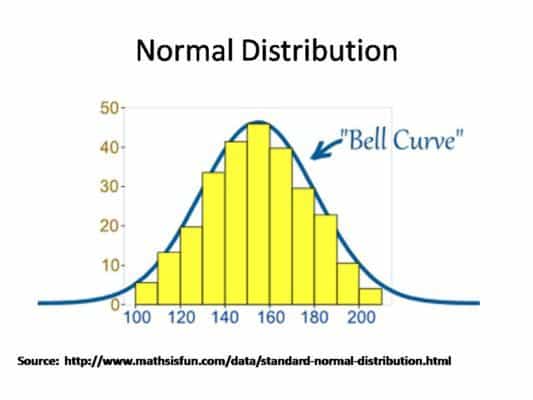
The x-axis would represent different BP ranges (above numbers are random) and the y-axis the probability for each BP range.
The average blood pressure has the highest probability (centre of the peak). Few have a BP higher than average (right of the peak) and few lower than average (left of the peak).
If we measure BP on enough number of people, we will always end up with this kind of distribution.
Most distributions tend to a normal distribution if the number of measurements increases. That is how nature/god works. There are a few exceptions (perfection is a gift that eludes even god!) – the stock market being the most notable!
Perhaps God lost money (like Newton did!) and cursed the markets!
You can google for examples of normal distribution and you will find it in different walks of life. At the IITs we use it to grade large classes, similar to what rating portals try to do.
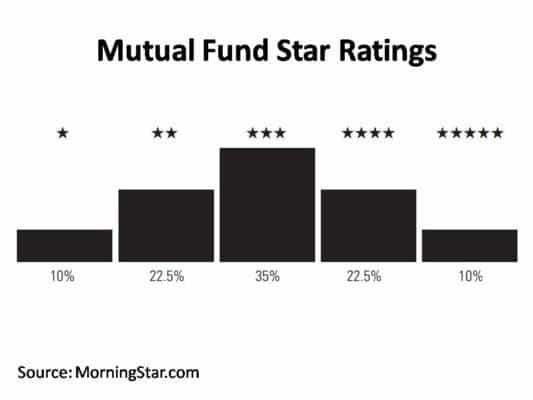
The standard deviation
Assuming a distribution is normal, the standard deviation play a pivotal role. The standard deviation is a measure of how much individual data points can deviation from the average.

The point is, once I have a normal distribution, I use the mean(average) which is the peak value and the standard deviation in the following way:
Expected value: average+/-standard deviation
Here the expected value refers to expectation up to 68% probability.
Annual returns S&P 500
The X-axis is return range and Y-axis probability of each return bin.
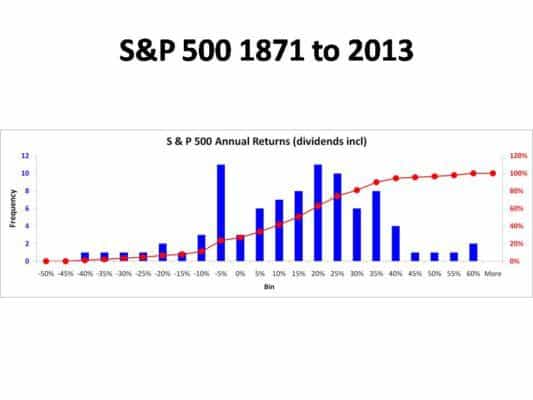
The Notice the absence of symmetry. The red line present the total probability count. You can ignore it.
Such a distribution is known as a skewed distribution.
Sensex Annual Return
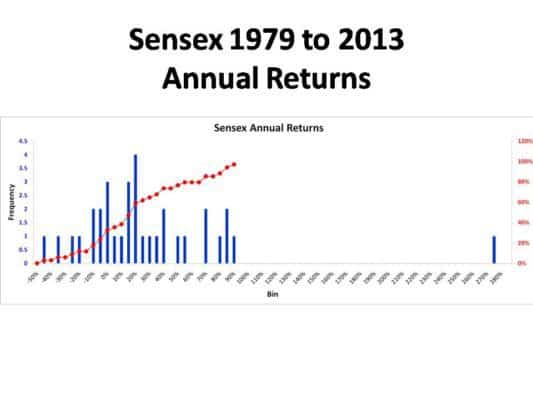
The lone point on the right is due to Mr. Harshad Mehta! Even if we remove that point, the rest of the points are not normal.
15 year CAGR distribution
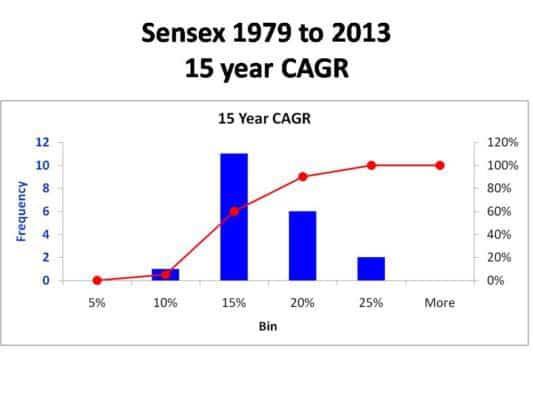
Still not normal and skewed to the right (which is probably a good thing!). In such distribution, the average return is meaningless. Instead of the average or mean, we should use the median. The median divides the distribution into two exact halves.
Fortunately, it is possible to transform a non-normal distribution to a normal distribution by using the square root of the returns instead of the returns.
Square root 15 Y distribution
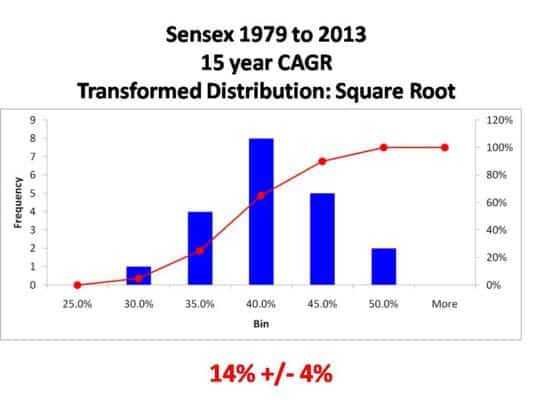
The x-axis here is the square root of the return. Exact values do not matter.
This distribution is not 100% normal but is nearly so. Therefore, the average and standard deviation are reasonable approximations.
Conclusion
Over a 15 year period, Sensex returns in the past (for buy-and-hold) have returned 14% on average, but with a spread of 4%.
That is returns can typically vary from 10% to 18%.
Therefore do not expect too much from equity: 10% is an extremely safe expectation; 12% is reasonable; 14% is borderline okay. Anything above that is nuts!

Join 32,000+ readers and get free money management solutions delivered to your inbox! Subscribe to get posts via email! (Link takes you to our email sign-up form)
🔥You can also avail massive discounts on our courses and the freefincal investor circle! 🔥& join our community of 8000+ users!
Track your mutual funds and stock investments with this Google Sheet!
We also publish monthly equity mutual funds, debt and hybrid mutual funds, index funds, and ETF screeners, as well as momentum and low-volatility stock screeners.
You can follow our articles on Google News

We have over 1,000 videos on YouTube!

Join our WhatsApp Channel



- Do you have a comment about the above article? Reach out to us on Twitter: @freefincal or @pattufreefincal
- Have a question? Subscribe to our newsletter using the form below.
- Hit 'reply' to any email from us! We do not offer personalised investment advice. We can write a detailed article without mentioning your name if you have a generic question.
Join 32,000+ readers and get free money management solutions delivered to your inbox! Subscribe to get posts via email! (Link takes you to our email sign-up form)
About The Author
Dr M. Pattabiraman (PhD) is the founder, managing editor and primary author of freefincal. He is an associate professor at the Indian Institute of Technology, Madras. He has over 14 years of experience publishing news analysis, research and financial product development. Connect with him via Twitter(X), LinkedIn, or YouTube. Pattabiraman has co-authored three print books: (1) You can be rich too with goal-based investing (CNBC TV18) for DIY investors. (2) Gamechanger for young earners. (3) Chinchu Gets a Superpower! for kids. He has also written seven other free e-books on various money management topics. He is a patron and co-founder of “Fee-only India,” an organisation promoting unbiased, commission-free, AUM-independent investment advice.
Pattabiraman has co-authored three print books: (1) You can be rich too with goal-based investing (CNBC TV18) for DIY investors. (2) Gamechanger for young earners. (3) Chinchu Gets a Superpower! for kids. He has also written seven other free e-books on various money management topics. He is a patron and co-founder of “Fee-only India,” an organisation promoting unbiased, commission-free, AUM-independent investment advice.Our flagship course! Learn to manage your portfolio like a pro to achieve your goals regardless of market conditions! ⇐ More than 3,500 investors and advisors are part of our exclusive community! Get clarity on how to plan for your goals and achieve the necessary corpus no matter the market condition!! Watch the first lecture for free! One-time payment! No recurring fees! Life-long access to videos! Reduce fear, uncertainty and doubt while investing! Learn how to plan for your goals before and after retirement with confidence.
Increase your income by getting people to pay for your skills! ⇐ More than 800 salaried employees, entrepreneurs and financial advisors are part of our exclusive community! Learn how to get people to pay for your skills! Whether you are a professional or small business owner seeking more clients through online visibility, or a salaried individual looking for a side income or passive income, we will show you how to achieve this by showcasing your skills and building a community that trusts and pays you. (watch 1st lecture for free). One-time payment! No recurring fees! Life-long access to videos!
Our book for kids: “Chinchu Gets a Superpower!” is now available!


Must-read book even for adults! This is something that every parent should teach their kids right from their young age. The importance of money management and decision making based on their wants and needs. Very nicely written in simple terms. - Arun.Buy the book: Chinchu gets a superpower for your child!
How to profit from content writing: Our new ebook is for those interested in getting a side income via content writing. It is available at a 50% discount for Rs. 500 only!
Do you want to check if the market is overvalued or undervalued? Use our market valuation tool (it will work with any index!), or get the Tactical Buy/Sell timing tool!
We publish monthly mutual fund screeners and momentum, low-volatility stock screeners.
About freefincal & its content policy. Freefincal is a News Media organisation dedicated to providing original analysis, reports, reviews and insights on mutual funds, stocks, investing, retirement and personal finance developments. We do so without conflict of interest and bias. Follow us on Google News. Freefincal serves more than three million readers a year (5 million page views) with articles based only on factual information and detailed analysis by its authors. All statements made will be verified with credible and knowledgeable sources before publication. Freefincal does not publish paid articles, promotions, PR, satire or opinions without data. All opinions will be inferences backed by verifiable, reproducible evidence/data. Contact Information: To get in touch, please use our contact form. (Sponsored posts or paid collaborations will not be entertained.)
Connect with us on social media
- Twitter @freefincal
- Subscribe to our YouTube Videos
- Posts feed via Feedburner.
Our publications
You Can Be Rich Too with Goal-Based Investing
 Published by CNBC TV18, this book is designed to help you ask the right questions and find the correct answers. Additionally, it comes with nine online calculators, allowing you to create custom solutions tailored to your lifestyle. Get it now.
Published by CNBC TV18, this book is designed to help you ask the right questions and find the correct answers. Additionally, it comes with nine online calculators, allowing you to create custom solutions tailored to your lifestyle. Get it now.Gamechanger: Forget Startups, Join Corporate & Still Live the Rich Life You Want
 This book is designed for young earners to get their basics right from the start! It will also help you travel to exotic places at a low cost! Get it or gift it to a young earner.
This book is designed for young earners to get their basics right from the start! It will also help you travel to exotic places at a low cost! Get it or gift it to a young earner.Your Ultimate Guide to Travel
 This is an in-depth exploration of vacation planning, including finding affordable flights, budget accommodations, and practical travel tips. It also examines the benefits of travelling slowly, both financially and psychologically, with links to relevant web pages and guidance at every step. Get the PDF for Rs 300 (instant download)
This is an in-depth exploration of vacation planning, including finding affordable flights, budget accommodations, and practical travel tips. It also examines the benefits of travelling slowly, both financially and psychologically, with links to relevant web pages and guidance at every step. Get the PDF for Rs 300 (instant download)